387 lines
27 KiB
Markdown
387 lines
27 KiB
Markdown
## AVS Device SDK v1.0.0
|
|
|
|
Please note the following for this release:
|
|
* Native components for the following capability agents are **not** included in v1.0 and will be added in future releases: `PlaybackController`, `Speaker`, and `Settings`.
|
|
* iHeartRadio is supported. Support for additional audio codecs, containers, streaming formats, and playlists will be included in future releases.
|
|
|
|
## Overview
|
|
|
|
The AVS Device SDK for C++ provides a modern C++ (11 or later) interface for the Alexa Voice Service (AVS) that allows developers to add intelligent voice control to connected products. It is modular and abstracted, providing components to handle discrete functionality such as speech capture, audio processing, and communications, with each component exposing APIs that you can use and customize for your integration. It also includes a sample app, which demonstrates interactions with the Alexa Voice Service (AVS).
|
|
|
|
To quickly setup your Raspberry Pi development environment or to learn how to optimize libcurl for size, [click here](https://github.com/alexa/alexa-client-sdk/wiki) to see the wiki.
|
|
|
|
* [Common Terms](#common-terms)
|
|
* [SDK Components](#sdk-components)
|
|
* [Minimum Requirements and Dependencies](#minimum-requirements-and-dependencies)
|
|
* [Prerequisites](#prerequisites)
|
|
* [Create an Out-of-Source Build](#create-an-out-of-source-build)
|
|
* [Run AuthServer](#run-authserver)
|
|
* [Run Unit Tests](#run-unit-tests)
|
|
* [Run Integration Tests](#run-integration-tests)
|
|
* [Run the Sample App](#run-the-sample-app)
|
|
* [AVS Device SDK for C++ API Documentation(Doxygen)](#alexa-client-sdk-api-documentation)
|
|
* [Resources and Guides](#resources-and-guides)
|
|
* [Release Notes](#release-notes)
|
|
|
|
## Common Terms
|
|
|
|
* **Interface** - A collection of logically grouped messages called **directives** and **events**, which correspond to client functionality, such speech recognition, audio playback, and volume control.
|
|
* **Directives** - Messages sent from AVS that instruct your product to take action.
|
|
* **Events** - Messages sent from your product to AVS notifying AVS something has occurred.
|
|
* **Downchannel** - A stream you create in your HTTP/2 connection, which is used to deliver directives from AVS to your product. The downchannel remains open in a half-closed state from the device and open from AVS for the life of the connection. The downchannel is primarily used to send cloud-initiated directives to your product.
|
|
* **Cloud-initiated Directives** - Directives sent from AVS to your product. For example, when a user adjusts device volume from the Amazon Alexa App, a directive is sent to your product without a corresponding voice request.
|
|
|
|
## SDK Components
|
|
|
|
This architecture diagram illustrates the data flows between components that comprise the AVS Device SDK for C++.
|
|
|
|
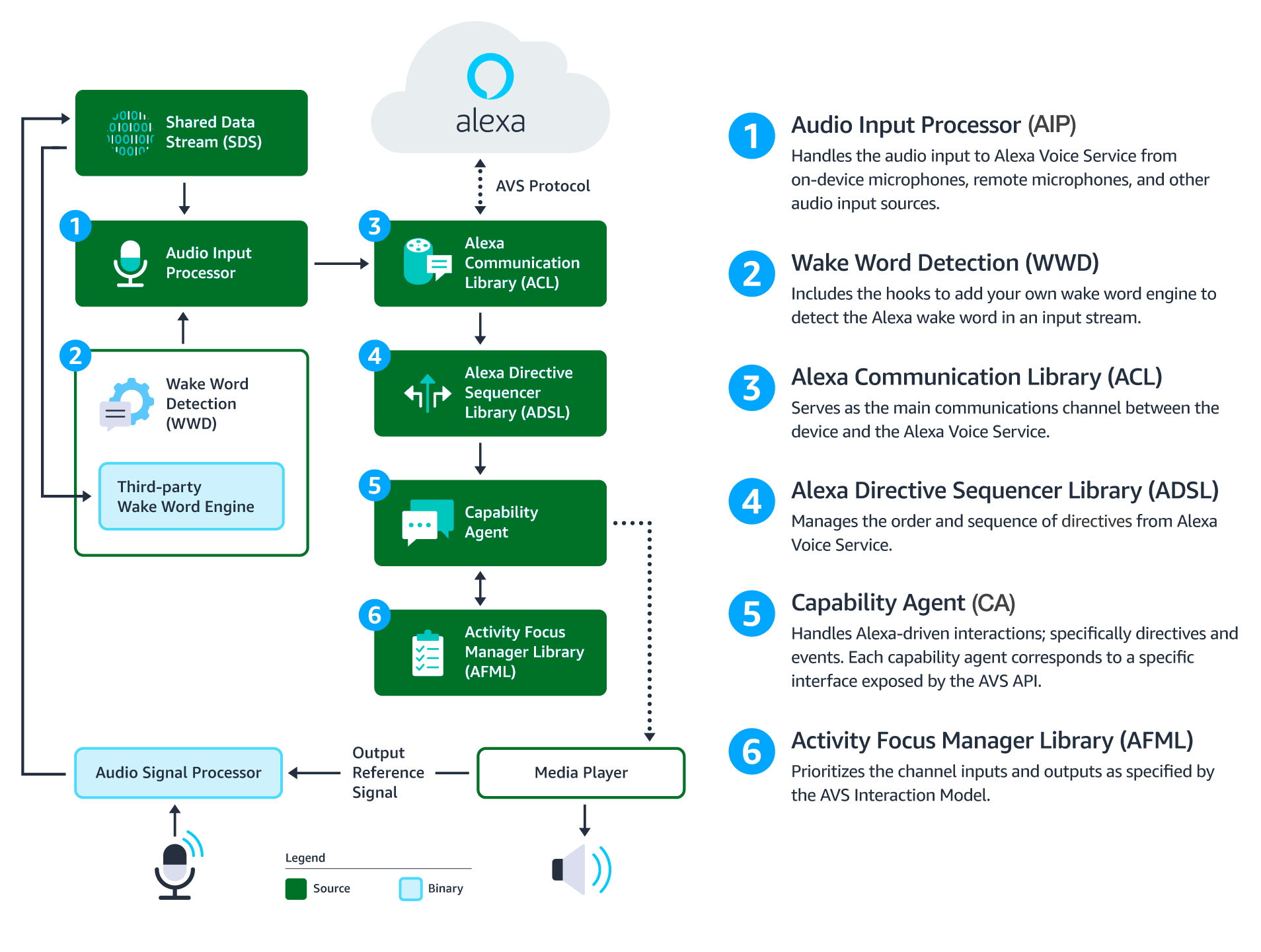
|
|
|
|
**Audio Signal Processor (ASP)** - Applies signal processing algorithms to both input and output audio channels. The applied algorithms are designed to produce clean audio data and include, but are not limited to: acoustic echo cancellation (AEC), beam forming (fixed or adaptive), voice activity detection (VAD), and dynamic range compression (DRC). If a multi-microphone array is present, the ASP constructs and outputs a single audio stream for the array.
|
|
|
|
**Shared Data Stream (SDS)** - A single producer, multi-consumer buffer that allows for the transport of any type of data between a single writer and one or more readers. SDS performs two key tasks: 1) it passes audio data between the audio front end (or Audio Signal Processor), the wake word engine, and the Alexa Communications Library (ACL) before sending to AVS; 2) it passes data attachments sent by AVS to specific capability agents via the ACL.
|
|
|
|
SDS is implemented atop a ring buffer on a product-specific memory segment (or user-specified), which allows it to be used for in-process or interprocess communication. Keep in mind, the writer and reader(s) may be in different threads or processes.
|
|
|
|
**Wake Word Engine (WWE)** - Spots wake words in an input stream. It is comprised of two binary interfaces. The first handles wake word spotting (or detection), and the second handles specific wake word models (in this case "Alexa"). Depending on your implementation, the WWE may run on the system on a chip (SOC) or dedicated chip, like a digital signal processor (DSP).
|
|
|
|
**Audio Input Processor (AIP)** - Handles audio input that is sent to AVS via the ACL. These include on-device microphones, remote microphones, an other audio input sources.
|
|
|
|
The AIP also includes the logic to switch between different audio input sources. Only one audio input source can be sent to AVS at a given time.
|
|
|
|
**Alexa Communications Library (ACL)** - Serves as the main communications channel between a client and AVS. The Performs two key functions:
|
|
|
|
* Establishes and maintains long-lived persistent connections with AVS. ACL adheres to the messaging specification detailed in [Managing an HTTP/2 Conncetion with AVS](https://developer.amazon.com/public/solutions/alexa/alexa-voice-service/docs/managing-an-http-2-connection).
|
|
* Provides message sending and receiving capabilities, which includes support JSON-formatted text, and binary audio content. For additional information, see [Structuring an HTTP/2 Request to AVS](https://developer.amazon.com/public/solutions/alexa/alexa-voice-service/docs/avs-http2-requests).
|
|
|
|
**Alexa Directive Sequencer Library (ADSL)**: Manages the order and sequence of directives from AVS, as detailed in the [AVS Interaction Model](https://developer.amazon.com/public/solutions/alexa/alexa-voice-service/reference/interaction-model#channels). This component manages the lifecycle of each directive, and informs the Directive Handler (which may or may not be a Capability Agent) to handle the message.
|
|
|
|
**Activity Focus Manager Library (AFML)**: Provides centralized management of audiovisual focus for the device. Focus is based on channels, as detailed in the [AVS Interaction Model](https://developer.amazon.com/public/solutions/alexa/alexa-voice-service/reference/interaction-model#channels), which are used to govern the prioritization of audiovisual inputs and outputs.
|
|
|
|
Channels can either be in the foreground or background. At any given time, only one channel can be in the foreground and have focus. If multiple channels are active, you need to respect the following priority order: Dialog > Alerts > Content. When a channel that is in the foreground becomes inactive, the next active channel in the priority order moves into the foreground.
|
|
|
|
Focus management is not specific to Capability Agents or Directive Handlers, and can be used by non-Alexa related agents as well. This allows all agents using the AFML to have a consistent focus across a device.
|
|
|
|
**Capability Agents**: Handle Alexa-driven interactions; specifically directives and events. Each capability agent corresponds to a specific interface exposed by the AVS API. These interfaces include:
|
|
|
|
* [SpeechRecognizer](https://developer.amazon.com/public/solutions/alexa/alexa-voice-service/reference/speechrecognizer) - The interface for speech capture.
|
|
* [SpeechSynthesizer](https://developer.amazon.com/public/solutions/alexa/alexa-voice-service/reference/speechsynthesizer) - The interface for Alexa speech output.
|
|
* [Alerts](https://developer.amazon.com/public/solutions/alexa/alexa-voice-service/reference/alerts) - The interface for setting, stopping, and deleting timers and alarms.
|
|
* [AudioPlayer](https://developer.amazon.com/public/solutions/alexa/alexa-voice-service/reference/audioplayer) - The interface for managing and controlling audio playback.
|
|
* [PlaybackController](https://developer.amazon.com/public/solutions/alexa/alexa-voice-service/reference/playbackcontroller) - The interface for navigating a playback queue via GUI or buttons.
|
|
* [Speaker](https://developer.amazon.com/public/solutions/alexa/alexa-voice-service/reference/speaker) - The interface for volume control, including mute and unmute.
|
|
* [System](https://developer.amazon.com/public/solutions/alexa/alexa-voice-service/reference/system) - The interface for communicating product status/state to AVS.
|
|
|
|
## Minimum Requirements and Dependencies
|
|
|
|
Instructions are available to help you quickly [setup a development environment for RaspberryPi](#resources-and-guides), and [build libcurl with nghttp2 for macOS](#resources-and-guides).
|
|
|
|
* C++ 11 or later
|
|
* [GNU Compiler Collection (GCC) 4.8.5](https://gcc.gnu.org/) or later **OR** [Clang 3.3](http://clang.llvm.org/get_started.html) or later
|
|
* [CMake 3.1](https://cmake.org/download/) or later
|
|
* [libcurl 7.50.2](https://curl.haxx.se/download.html) or later
|
|
* [nghttp2 1.0](https://github.com/nghttp2/nghttp2) or later
|
|
* [OpenSSL 1.0.2](https://www.openssl.org/source/) or later
|
|
* [Doxygen 1.8.13](http://www.stack.nl/~dimitri/doxygen/download.html) or later (required to build API documentation)
|
|
* [SQLite 3.19.3](https://www.sqlite.org/download.html) or later (required for Alerts)
|
|
* For Alerts to work as expected:
|
|
* The device system clock must be set to UTC time. We recommend using `NTP` to do this
|
|
* A filesystem is required
|
|
|
|
**MediaPlayer Reference Implementation Dependencies**
|
|
Building the reference implementation of the `MediaPlayerInterface` (the class `MediaPlayer`) is optional, but requires:
|
|
* [GStreamer 1.8](https://gstreamer.freedesktop.org/documentation/installing/index.html) or later and the following GStreamer plug-ins:
|
|
**IMPORTANT NOTE FOR MACOS**: GStreamer 1.10.4 has been validated for macOS. GStreamer 1.12 **does not** work.
|
|
* [GStreamer Base Plugins 1.8](https://gstreamer.freedesktop.org/releases/gst-plugins-base/1.8.0.html) or later.
|
|
* [GStreamer Good Plugins 1.8](https://gstreamer.freedesktop.org/releases/gst-plugins-good/1.8.0.html) or later.
|
|
* [GStreamer Libav Plugin 1.8](https://gstreamer.freedesktop.org/releases/gst-libav/1.8.0.html) or later **OR**
|
|
[GStreamer Ugly Plugins 1.8](https://gstreamer.freedesktop.org/releases/gst-plugins-ugly/1.8.0.html) or later, for decoding MP3 data.
|
|
|
|
**NOTE**: The plugins may depend on libraries which need to be installed for the GStreamer based `MediaPlayer` to work correctly.
|
|
|
|
**Sample App Dependencies**
|
|
Building the sample app is optional, but requires:
|
|
* [PortAudio v190600_20161030](http://www.portaudio.com/download.html)
|
|
* GStreamer
|
|
|
|
**NOTE**: The sample app will work with or without a wake word engine. If built without a wake word engine, hands-free mode will be disabled in the sample app.
|
|
|
|
## Prerequisites
|
|
|
|
Before you create your build, you'll need to install some software that is required to run `AuthServer`. `AuthServer` is a minimal authorization server built in Python using Flask. It provides an easy way to obtain your first refresh token, which will be used for integration tests and obtaining access token that are required for all interactions with AVS.
|
|
|
|
**IMPORTANT NOTE**: `AuthServer` is for testing purposed only. A commercial product is expected to obtain Login with Amazon (LWA) credentials using the instructions provided on the Amazon Developer Portal for **Remote Authorization** and **Local Authorization**. For additional information, see [AVS Authorization](https://developer.amazon.com/public/solutions/alexa/alexa-voice-service/content/avs-api-overview#authorization).
|
|
|
|
### Step 1: Install `pip`
|
|
|
|
If `pip` isn't installed on your system, follow the detailed install instructions [here](https://packaging.python.org/installing/#install-pip-setuptools-and-wheel).
|
|
|
|
### Step 2: Install `flask` and `requests`
|
|
|
|
For Windows run this command:
|
|
|
|
```
|
|
pip install flask requests
|
|
```
|
|
|
|
For Unix/Mac run this command:
|
|
|
|
```
|
|
pip install --user flask requests
|
|
```
|
|
|
|
### Step 3: Obtain Your Device Type ID, Cliend ID, and Client Secret
|
|
|
|
If you haven't already, follow these instructions to [register a product and create a security profile](https://github.com/alexa/alexa-avs-sample-app/wiki/Create-Security-Profile).
|
|
|
|
Make sure you note the following, you'll need these later when you configure `AuthServer`:
|
|
|
|
* Device Type ID
|
|
* Client ID
|
|
* Client Secret
|
|
|
|
**IMPORTANT NOTE**: Make sure that you've set your **Allowed Origins** and **Allowed Return URLs** in the **Web Settings Tab**:
|
|
* Allowed Origins: http://localhost:3000
|
|
* Allowed Return URLs: http://localhost:3000/authresponse
|
|
|
|
## Create an Out-of-Source Build
|
|
|
|
The following instructions assume that all requirements and dependencies are met and that you have cloned the repository (or saved the tarball locally).
|
|
|
|
### CMake Build Types and Options
|
|
|
|
The following build types are supported:
|
|
|
|
* `DEBUG` - Shows debug logs with `-g` compiler flag.
|
|
* `RELEASE` - Adds `-O2` flag and removes `-g` flag.
|
|
* `MINSIZEREL` - Compiles with `RELEASE` flags and optimizations (`-O`s) for a smaller build size.
|
|
|
|
To specify a build type, use this command in place of step 4 below:
|
|
`cmake <path-to-source> -DCMAKE_BUILD_TYPE=<build-type>`
|
|
|
|
### Build with a Wake Word Detector
|
|
|
|
**Note**: Wake word detector and key word detector (KWD) are used interchangeably.
|
|
|
|
The AVS Device SDK for C++ supports wake word detectors from [Sensory](https://github.com/Sensory/alexa-rpi) and [KITT.ai](https://github.com/Kitt-AI/snowboy/). The following options are required to build with a wake word detector, please replace `<wake-word-name>` with `SENSORY` for Sensory, and `KITTAI` for KITT.ai:
|
|
|
|
* `-D<wake-word-name>_KEY_WORD_DETECTOR=<ON or OFF>` - Specifies if the wake word detector is enabled or disabled during build.
|
|
* `-D<wake-word-name>_KEY_WORD_DETECTOR_LIB_PATH=<path-to-lib>` - The path to the wake word detector library.
|
|
* `-D<wake-word-name>_KEY_WORD_DETECTOR_INCLUDE_DIR=<path-to-include-dir>` - The path to the wake word detector include directory.
|
|
|
|
**Note**: To list all available CMake options, use the following command: `-LH`.
|
|
|
|
#### Sensory
|
|
|
|
If using the Sensory wake word detector, version [5.0.0-beta.10.2](https://github.com/Sensory/alexa-rpi) or later is required.
|
|
|
|
This is an example `cmake` command to build with Sensory:
|
|
|
|
```
|
|
cmake <path-to-source> -DSENSORY_KEY_WORD_DETECTOR=ON -DSENSORY_KEY_WORD_DETECTOR_LIB_PATH=.../alexa-rpi/lib/libsnsr.a -DSENSORY_KEY_WORD_DETECTOR_INCLUDE_DIR=.../alexa-rpi/include
|
|
```
|
|
|
|
Note that you may need to license the Sensory library for use prior to running cmake and building it into the SDK. A script to license the Sensory library can be found on the Sensory [Github](https://github.com/Sensory/alexa-rpi) page under `bin/license.sh`.
|
|
|
|
#### KITT.ai
|
|
|
|
A matrix calculation library, known as BLAS, is required to use KITT.ai. The following are sample commands to install this library:
|
|
* Generic Linux - `apt-get install libatlas-base-dev`
|
|
* macOS - `brew install homebrew/science/openblas`
|
|
|
|
This is an example `cmake` command to build with KITT.ai:
|
|
|
|
```
|
|
cmake <path-to-source> -DKITTAI_KEY_WORD_DETECTOR=ON -DKITTAI_KEY_WORD_DETECTOR_LIB_PATH=.../snowboy-1.2.0/lib/libsnowboy-detect.a -DKITTAI_KEY_WORD_DETECTOR_INCLUDE_DIR=.../snowboy-1.2.0/include
|
|
```
|
|
|
|
### Build with an implementation of `MediaPlayer`
|
|
|
|
`MediaPlayer` (the reference implementation of the `MediaPlayerInterface`) is based upon [GStreamer](https://gstreamer.freedesktop.org/), and is not built by default. To build 'MediaPlayer' the `-DGSTREAMER_MEDIA_PLAYER=ON` option must be specified to CMake.
|
|
|
|
If GStreamer was [installed from source](https://gstreamer.freedesktop.org/documentation/frequently-asked-questions/getting.html), the prefix path provided when building must be specified to CMake with the `DCMAKE_PREFIX_PATH` option.
|
|
|
|
This is an example `cmake` command:
|
|
|
|
```
|
|
cmake <path-to-source> -DGSTREAMER_MEDIA_PLAYER=ON -DCMAKE_PREFIX_PATH=<path-to-GStreamer-build>
|
|
```
|
|
|
|
### Build with PortAudio (Required to Run the Sample App)
|
|
|
|
PortAudio is required to build and run the AVS Device SDK for C++ Sample App. Build instructions are available for [Linux](http://portaudio.com/docs/v19-doxydocs/compile_linux.html) and [macOS](http://portaudio.com/docs/v19-doxydocs/compile_mac_coreaudio.html).
|
|
|
|
This is sample CMake command to build the AVS Device SDK for C++ with PortAudio:
|
|
|
|
```
|
|
cmake <path-to-source> -DPORTAUDIO=ON
|
|
-DPORTAUDIO_LIB_PATH=<path-to-portaudio-lib>
|
|
-DPORTAUDIO_INCLUDE_DIR=<path-to-portaudio-include-dir>
|
|
```
|
|
|
|
For example,
|
|
```
|
|
cmake <path-to-source> -DPORTAUDIO=ON
|
|
-DPORTAUDIO_LIB_PATH=.../portaudio/lib/.libs/libportaudio.a
|
|
-DPORTAUDIO_INCLUDE_DIR=.../portaudio/include
|
|
```
|
|
|
|
## Build for Generic Linux / Raspberry Pi / macOS
|
|
|
|
To create an out-of-source build:
|
|
|
|
1. Clone the repository (or download and extract the tarball).
|
|
2. Create a build directory out-of-source. **Important**: The directory cannot be a subdirectory of the source folder.
|
|
3. `cd` into your build directory.
|
|
4. From your build directory, run `cmake` on the source directory to generate make files for the SDK: `cmake <path-to-source-code>`.
|
|
5. After you've successfully run `cmake`, you should see the following message: `-- Please fill <path-to-build-directory>/Integration/AlexaClientSDKConfig.json before you execute integration tests.`. Open `Integration/AlexaClientSDKConfig.json` with your favorite text editor and fill in your product information.
|
|
6. From the build directory, run `make` to build the SDK.
|
|
|
|
### Application Settings
|
|
|
|
The SDK will require a configuration JSON file, an example of which is located in `Integration/AlexaClientSDKConfig.json`. The contents of the JSON should be populated with your product information (which you got from the developer portal when registering a product and creating a security profile), and the location of your database and sound files. This JSON file is required for the integration tests to work properly, as well as for the Sample App.
|
|
|
|
The layout of the file is as follows:
|
|
|
|
```json
|
|
{
|
|
"authDelegate":{
|
|
"deviceTypeId":"<Device Type ID for your device on the Developer portal>",
|
|
"clientId":"<ClientID for the security profile of the device>",
|
|
"clientSecret":"<ClientSecret for the security profile of the device>",
|
|
"deviceSerialNumber":"<a unique number for your device>"
|
|
},
|
|
"alertsCapabilityAgent": {
|
|
"databaseFilePath":"/<path-to-db-directory>/<db-file-name>",
|
|
"alarmSoundFilePath":"/<path-to-alarm-sound>/alarm_normal.mp3",
|
|
"alarmShortSoundFilePath":"/<path-to-short-alarm-sound>/alarm_short.wav",
|
|
"timerSoundFilePath":"/<path-to-timer-sound>/timer_normal.mp3",
|
|
"timerShortSoundFilePath":"/<path-to-short-timer-sound>/timer_short.wav"
|
|
}
|
|
}
|
|
```
|
|
**NOTE**: The `deviceSerialNumber` is a unique identifier that you create. It is **not** provided by Amazon.
|
|
**NOTE**: Audio assets included in this repository are licensed as "Alexa Materials" under the [Alexa Voice
|
|
Service Agreement](https://developer.amazon.com/public/solutions/alexa/alexa-voice-service/support/terms-and-agreements).
|
|
|
|
## Run AuthServer
|
|
|
|
After you've created your out-of-source build, the next step is to run `AuthServer` to retrieve a valid refresh token from LWA.
|
|
|
|
* Run this command to start `AuthServer`:
|
|
```
|
|
python AuthServer/AuthServer.py
|
|
```
|
|
You should see a message that indicates the server is running.
|
|
* Open your favorite browser and navigate to: `http://localhost:3000`
|
|
* Follow the on-screen instructions.
|
|
* After you've entered your credentials, the server should terminate itself, and `Integration/AlexaClientSDKConfig.json` will be populated with your refresh token.
|
|
* Before you proceed, it's important that you make sure the refresh token is in `Integration/AlexaClientSDKConfig.json`.
|
|
|
|
## Run Unit Tests
|
|
|
|
Unit tests for the AVS Device SDK for C++ use the [Google Test](https://github.com/google/googletest) framework. Ensure that the [Google Test](https://github.com/google/googletest) is installed, then run the following command:
|
|
`make all test`
|
|
|
|
Ensure that all tests are passed before you begin integration testing.
|
|
|
|
### Run Unit Tests with Sensory Enabled
|
|
|
|
In order to run unit tests for the Sensory wake word detector, the following files must be downloaded from [GitHub](https://github.com/Sensory/alexa-rpi) and placed in `<source dir>/KWD/inputs/SensoryModels` for the integration tests to run properly:
|
|
|
|
* [`spot-alexa-rpi-31000.snsr`](https://github.com/Sensory/alexa-rpi/blob/master/models/spot-alexa-rpi-31000.snsr)
|
|
|
|
### Run Unit Tests with KITT.ai Enabled
|
|
|
|
In order to run unit tests for the KITT.ai wake word detector, the following files must be downloaded from [GitHub](https://github.com/Kitt-AI/snowboy/tree/master/resources) and placed in `<source dir>/KWD/inputs/KittAiModels`:
|
|
* [`common.res`](https://github.com/Kitt-AI/snowboy/tree/master/resources)
|
|
* [`alexa.umdl`](https://github.com/Kitt-AI/snowboy/tree/master/resources/alexa/alexa-avs-sample-app) - It's important that you download the `alexa.umdl` in `resources/alexa/alexa-avs-sample-app` for the KITT.ai unit tests to run properly.
|
|
|
|
## Run Integration Tests
|
|
|
|
Integration tests ensure that your build can make a request and receive a response from AVS.
|
|
* All requests to AVS require auth credentials
|
|
* The integration tests for Alerts require your system to be in UTC
|
|
|
|
**Important**: Integration tests reference an `AlexaClientSDKConfig.json` file, which you must create.
|
|
See the `Create the AlexaClientSDKConfig.json file` section (above), if you have not already done this.
|
|
|
|
To exercise the integration tests run this command:
|
|
`TZ=UTC make all integration`
|
|
|
|
### Run Integration Tests with Sensory Enabled
|
|
|
|
If the project was built with the Sensory wake word detector, the following files must be downloaded from [GitHub](https://github.com/Sensory/alexa-rpi) and placed in `<source dir>/Integration/inputs/SensoryModels` for the integration tests to run properly:
|
|
|
|
* [`spot-alexa-rpi-31000.snsr`](https://github.com/Sensory/alexa-rpi/blob/master/models/spot-alexa-rpi-31000.snsr)
|
|
|
|
### Run Integration Tests with KITT.ai
|
|
|
|
If the project was built with the KITT.ai wake word detector, the following files must be downloaded from [GitHub](https://github.com/Kitt-AI/snowboy/tree/master/resources) and placed in `<source dir>/Integration/inputs/KittAiModels` for the integration tests to run properly:
|
|
* [`common.res`](https://github.com/Kitt-AI/snowboy/tree/master/resources)
|
|
* [`alexa.umdl`](https://github.com/Kitt-AI/snowboy/tree/master/resources/alexa/alexa-avs-sample-app) - It's important that you download the `alexa.umdl` in `resources/alexa/alexa-avs-sample-app` for the KITT.ai integration tests to run properly.
|
|
|
|
## Run the Sample App
|
|
|
|
**Note**: Building with PortAudio and GStreamer is required.
|
|
|
|
Before you run the sample app, it's important to note that the application takes two arguments. The first is required, and is the path to `AlexaClientSDKConfig.json`. The second is only required if you are building the sample app with wake word support, and is the path of the of the folder containing the wake word engine models.
|
|
|
|
Navigate to the `SampleApp/src` folder from your build directory. Then run this command:
|
|
|
|
```
|
|
TZ=UTC ./SampleApp <REQUIRED-path-to-config-json> <OPTIONAL-path-to-wake-word-engine-folder-enclosing-model-files> <OPTIONAL-log-level>
|
|
```
|
|
|
|
**Note**: The following logging levels are supported with `DEBUG9` providing the highest and `CRITICAL` the lowest level of logging: `DEBUG9`, `DEBUG8`, `DEBUG7`, `DEBUG6`, `DEBUG5`, `DEBUG4`, `DEBUG3`, `DEBUG2`, `DEBUG1`, `DEBUG0`, `INFO`, `WARN`, `ERROR`, and `CRITICAL`.
|
|
|
|
**Note**: The user must wait several seconds after starting up the sample app before the sample app is properly usable.
|
|
|
|
## AVS Device SDK for C++ API Documentation
|
|
|
|
To build API documentation locally, run this command from your build directory: `make doc`.
|
|
|
|
## Resources and Guides
|
|
|
|
* [How To Setup Your Raspberry Pi Development Environment](https://github.com/alexa/alexa-client-sdk/wiki/How-to-build-your-raspberrypi-development-environment)
|
|
* [How To Build libcurl with nghttp2 on macOS](https://github.com/alexa/alexa-client-sdk/wiki/How-to-build-libcurl-with-nghttp2-for-macos)
|
|
* [Step-by-step instructions to optimize libcurl for size in `*nix` systems](https://github.com/alexa/alexa-client-sdk/wiki/optimize-libcurl).
|
|
* [Step-by-step instructions to build libcurl with mbed TLS and nghttp2 for `*nix` systems](https://github.com/alexa/alexa-client-sdk/wiki/build-libcurl-with-mbed-TLS-and-nghttp2).
|
|
|
|
## Appendix A: Runtime Configuration of path to CA Certificates
|
|
|
|
By default libcurl is built with paths to a CA bundle and a directory containing CA certificates. You can direct the AVS Device SDK for C++ to configure libcurl to use an additional path to directories containing CA certificates via the [CURLOPT_CAPATH](https://curl.haxx.se/libcurl/c/CURLOPT_CAPATH.html) setting. This is done by adding a `"libcurlUtils/CURLOPT_CAPATH"` entry to the `AlexaClientSDKConfig.json` file. Here is an example:
|
|
|
|
```
|
|
{
|
|
"authDelegate" : {
|
|
"clientId" : "INSERT_YOUR_CLIENT_ID_HERE",
|
|
"refreshToken" : "INSERT_YOUR_REFRESH_TOKEN_HERE",
|
|
"clientSecret" : "INSERT_YOUR_CLIENT_SECRET_HERE"
|
|
},
|
|
"libcurlUtils" : {
|
|
"CURLOPT_CAPATH" : "INSERT_YOUR_CA_CERTIFICATE_PATH_HERE"
|
|
}
|
|
}
|
|
```
|
|
**Note** If you want to assure that libcurl is *only* using CA certificates from this path you may need to reconfigure libcurl with the `--without-ca-bundle` and `--without-ca-path` options and rebuild it to suppress the default paths. See [The libcurl documention](https://curl.haxx.se/docs/sslcerts.html) for more information.
|
|
|
|
## Release Notes
|
|
|
|
**Note**: Features, updates, and resolved issues from previous releases are available to view in [CHANGELOG.md](https://github.com/alexa/alexa-client-sdk/blob/master/CHANGELOG.md).
|
|
|
|
v1.0.0 released 8/7/2017:
|
|
* Features
|
|
* Native components for the following capability agents are included in this release: `Alerts`, `AudioPlayer`, `SpeechRecognizer`, `SpeechSynthesizer`, and `System`
|
|
* Supports iHeartRadio
|
|
* Includes a sample application to demonstrate interactions with AVS
|
|
* Known Issues
|
|
* Native components for the following capability agents are **not** included in this release: `PlaybackController`, `Speaker`, `Settings`, `TemplateRuntime`, and `Notifications`
|
|
* Amazon Music, TuneIn, and SiriusXM are not supported in v1.0
|
|
* The `AlertsCapabilityAgent` satisfies the [AVS specification](https://developer.amazon.com/public/solutions/alexa/alexa-voice-service/reference/timers-and-alarms-conceptual-overview) except for sending retrospective events. For example, sending `AlertStarted` for an Alert which rendered when there was no internet connection.
|
|
* `ACL`'s asynchronous receipt of audio attachments may manage resources poorly in scenarios where attachments are received but not consumed.
|
|
* When an `AttachmentReader` does not deliver data for prolonged periods, `MediaPlayer` may not resume playing the delayed audio.
|
|
* Without the refresh token in the JSON file, the sample app crashes on start up.
|
|
* Any connection loss during the `Listening` state keeps the app stuck in this state, unless the ongoing interaction is manually stopped by the user.
|
|
* The user must wait several seconds after starting up the sample app before the sample app is properly usable.
|